Abstract
We demonstrate the existence of universal adversarial perturbations, which can fool a family of audio classification architectures, for both targeted and untargeted attack scenarios. We propose two methods for finding such perturbations. The first method is based on an iterative, greedy approach that is well-known in computer vision computer vision, it aggregates small perturbations to the input so as to push it to the decision boundary. The second method, which is the main contribution of this work, is a novel penalty formulation, which finds targeted and untargeted universal adversarial perturbations, Differently from the greedy approach, the penalty method minimizes an appropriate objective function on a batch of samples. Therefore, it produces more successful attacks when the number of training samples is limited. Moreover, we provide a proof that the proposed penalty method theoretically converges to a solution that corresponds to universal adversarial perturbations. We also demonstrate that it is possible to provide successful attacks using the penalty method when only one sample from the target dataset is available for the attacker. Experimental results on attacking various 1D CNN architectures have shown attack success rates higher than 85.0% and 83.1% for targeted and untargeted attacks, respectively using the proposed penalty method.
Listen to some adversarial audio examples below:
The target model is the winner of TensorFlow Speech Recognition Challenge, SpchCMD. The model is traind by Speech Commands dataset for speech commands calssification
Original sample (True Class “Up”)
adversarial sample by Iterative method (Detected Class Unknown, SNR: 25.385, dBx(V): -18.416)
adversarial sample by Penalty method (Detected Class Unknown, SNR: 24.773, dBx(V): -20.319)
Original sample (True Class: “One”)
adversarial sample by Iterative method (Detected Class: Seven, SNR: 29.351, dBx(V): -20.292)
adversarial sample by Penalty method (Detected Class: Seven, SNR: 27.276, dBx(V): -21.299)
Original sample (True Class: “No”)
adversarial sample by Iterative method (Detected Class: Sheila, SNR: 28.845, dBx(V): -18.416)
adversarial sample by Penalty method (Detected Class: Sheila, SNR: 27.316, dBx(V): -24.840)
Original sample (True Class: “Two”)
adversarial sample by Iterative method (Detected Class: Sheila, SNR: 26.627, dBx(V): -24.813)
adversarial sample by Penalty method (Detected Class: Sheila, SNR: 28.200, dBx(V): -18.416)
Original sample (True Class: “Right”)
adversarial sample by Iterative method (Detected Class: Sheila, SNR: 25.784, dBx(V): -24.838)
adversarial sample by Penalty method (Detected Class: Sheila, SNR: 287.580, dBx(V): -18.416)
The target model is SINCNET. The model is traind by Urbansound8k dataset for environmental sound classification:
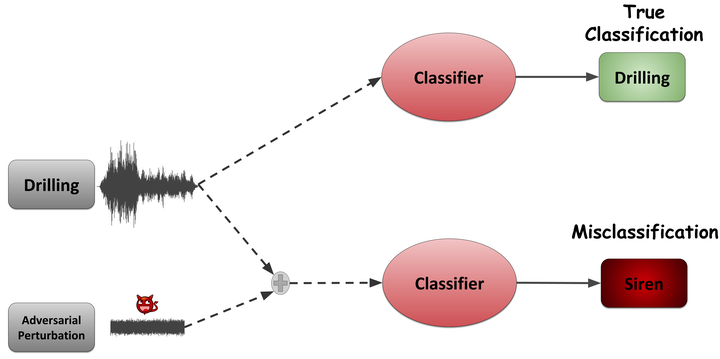
Original sample (True Class: Driling)
adversarial sample by Iterative method (Detected Class: Gun shot, SNR: 27.025, dBx(V): -18.416)
adversarial sample by Penalty method (Detected Class: Gun shot, SNR: 28.040, dBx(V): -29.264)
Original sample (True Class: Siren)
adversarial sample by Iterative method (Detected Class: Airconditioner, SNR: 29.244, dBx(V): -20.101)
adversarial sample by Penalty method (Detected Class: Airconditioner, SNR: 33.766, dBx(V): -35.153)
Original sample (True Class: Children playing)
adversarial sample by Iterative method (Detected Class: Dog bark, SNR: 31.784, dBx(V): -24.369)
adversarial sample by Penalty method (Detected Class: Dog bark, SNR: 33.207, dBx(V): -35.154)
Original sample (True Class: Street music)
adversarial sample by Iterative method (Detected Class: Airconditioner, SNR: 28.994, dBx(V): -20.101)
adversarial sample by Penalty method (Detected Class: Airconditioner, SNR: 33.539, dBx(V): -35.126)
Sajjad Abdoli
Ph.D. Founding AI Scientist
My research interests include Audio and Speech Processing, Music Information Retrieval, Adversarial Machine Learning and object localization/classification.