End-to-end environmental sound classification using a 1D convolutional neural network
Abstract
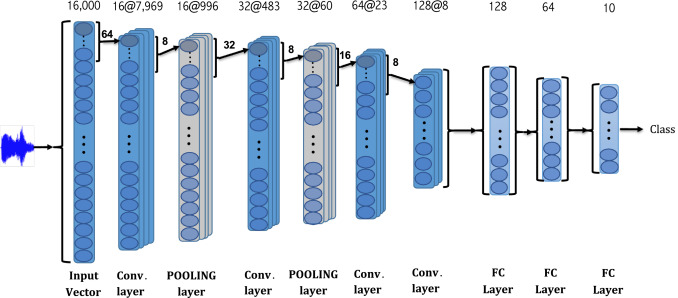
In this paper, we present an end-to-end approach for environmental sound classification based on a 1D Convolution Neural Network (CNN) that learns a representation directly from the audio signal. Several convolutional layers are used to capture the signal’s fine time structure and learn diverse filters that are relevant to the classification task. The proposed approach can deal with audio signals of any length as it splits the signal into overlapped frames using a sliding window. Different architectures considering several input sizes are evaluated, including the initialization of the first convolutional layer with a Gammatone filterbank that models the human auditory filter response in the cochlea. The performance of the proposed end-to-end approach in classifying environmental sounds was assessed on the UrbanSound8k dataset and the experimental results have shown that it achieves 89% of mean accuracy. Therefore, the proposed approach outperforms most of the state-of-the-art approaches that use handcrafted features or 2D representations as input. Moreover, the proposed approach outperforms all approaches that use raw audio signal as input to the classifier. Furthermore, the proposed approach has a small number of parameters compared to other architectures found in the literature, which reduces the amount of data required for training.
Sajjad Abdoli
Ph.D. Founding AI Scientist
My research interests include Audio and Speech Processing, Music Information Retrieval, Adversarial Machine Learning and object localization/classification.